[My study] Application of Large Language Models in Developing Pet-Companion-Friendly Veterinary Services
2024-04-25 Korean Society of Veterinary Science (KSVS) conference poster presentation
Introduction
Large language models in medicine and veterinary medicine
- Recent trends in human precision medicine are to adopt large language models (LLMs) for big data analysis.
- LLMs have shown promising results in human medical applications for research, educational, and clinical applications, including use-cases of clinical text summarization, clinical decision support, and patient risk stratification, which could notably increase productivity for clinicians and pursue patient-led healthcare services.
- The veterinary field is also poised to leverage the state-of-the-art methodologies aimed at companion animal guardians and clinical practitioners.
- Especially the assessment of health status or urgency and guiding timely visits to animal hospitals can provide immediate opportunities for it.
- Therefore, this study investigates the feasibility of LLMs in developing pet-companion-friendly, veterinary-specific services.
Methods
Data collection and preprocessing
- 280 consultation record cases (courtesy of Dr.Tail company, a leading professional veterinarian teleadvice service in the U.S.) were used in this study. These cases were pre-categorized by Dr.Tail into seven distinct groups: diarrhea, vomiting, skin, ear, eye, behavior, and others.
- The dataset, with 280 cases across seven categories, was split into training and testing sets at a 3:1 ratio, resulting in 210 training and 70 testing cases, stratified by consultation date.
Workflow of model development
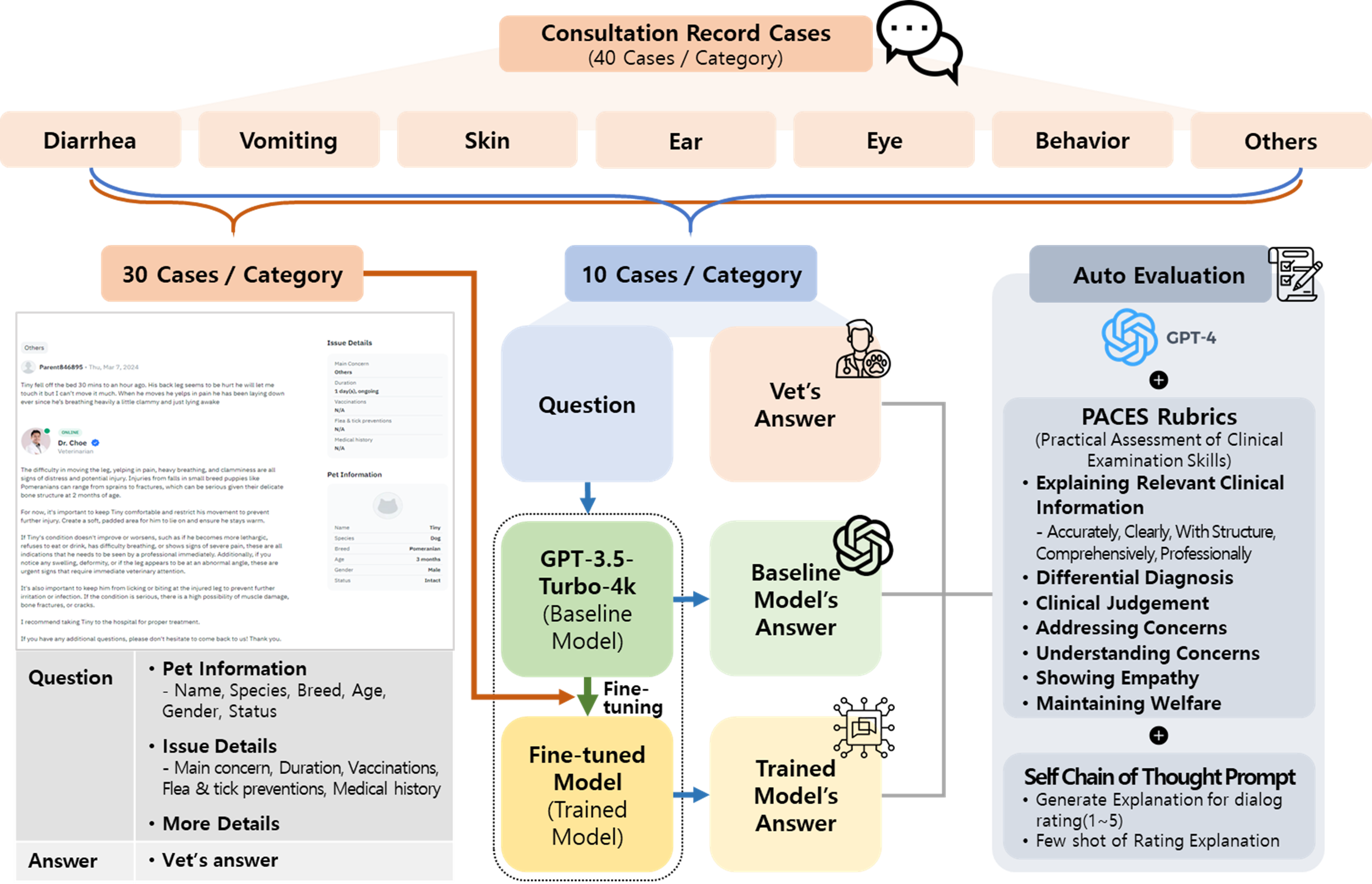
Model development and fine-tuning
- The fine-tuning process involved providing the model with system instructions, user prompts (questions), and corresponding veterinarians’ answers.
- Fine-tuning parameters : number of epochs= 3, batch size= 1, learning rate multiplier= 1.
- Inference parameters : temperature= 0.1, max_tokens= 500, top_p= 0.95, frequency_penalty= 0, presence_penalty= 0, stop= None.
Evaluation benchmarks and auto-evaluation methodology
- The ‘trained model’s performance was assessed using the advanced GPT-4 model through an auto-evaluation approach. (Iterated five times)
- The assessment utilized the Practical Assessment of Clinical Examination Skills (PACES) rubrics developed by the Royal College of Physicians in the U.K.
- The Self-Chain-of-Thought (Self-CoT) prompting led the model to generate critiques and summaries by analyzing scores and example answers for each score range (1-5). This included identifying good and bad views of each answer and summarizing these insights, enabling the model to deepen its understanding of the scoring criteria.
- These analyses were taken as inputs in a few-shot learning setup, refining the model’s evaluation skills through repeated self-review.
- By applying the previously validated auto-evaluation methodology with self-CoT in human medicine research (AMIE by Google Research and Google DeepMind), the auto-evaluation process became accurate and reliable.
Results
Score comparison: trained model vs. baseline model
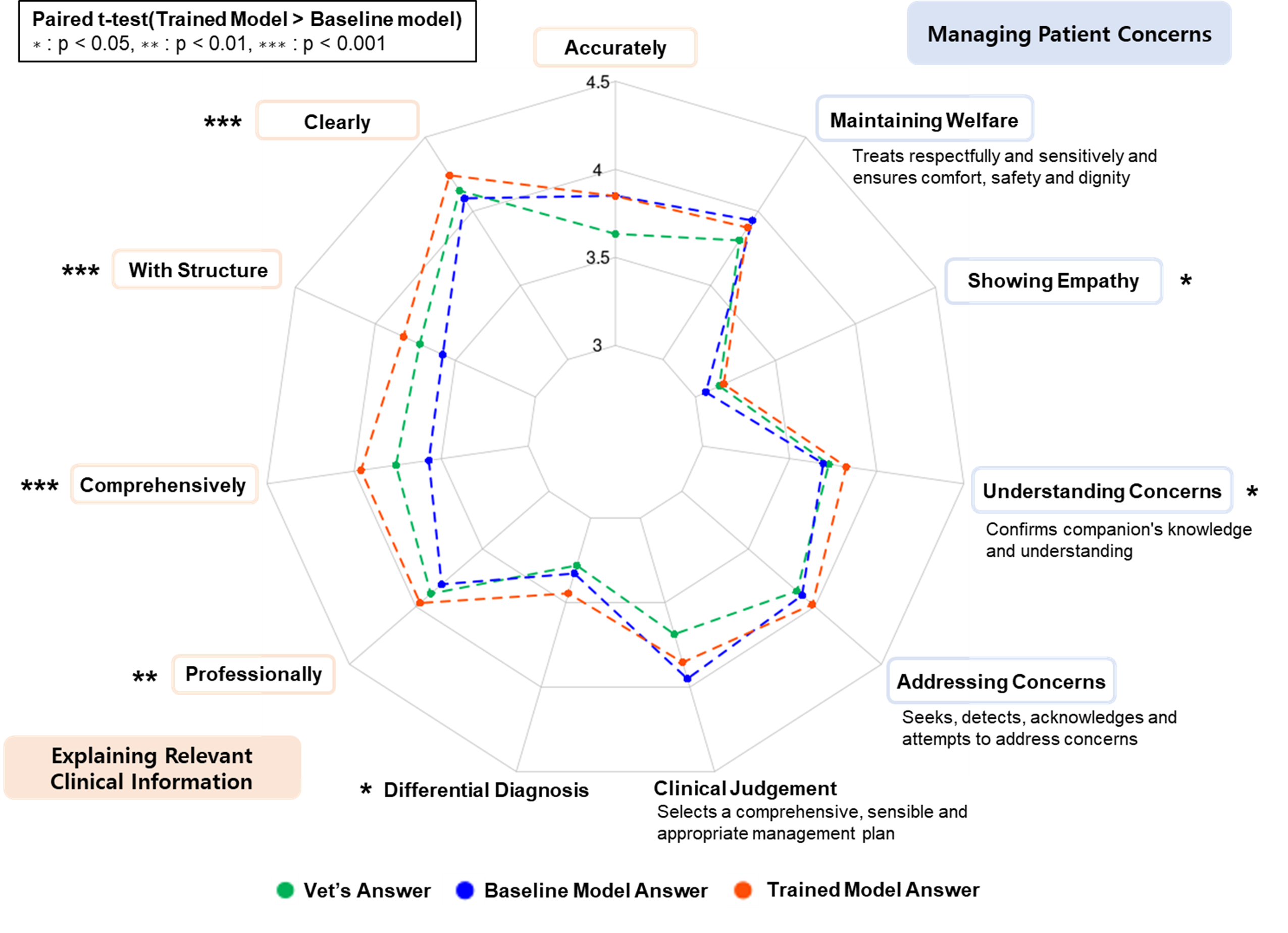
Discussion
The effectiveness of veterinary dialogue training
- Even training with a small size of consultation cases statistically improved most of the multiple evaluation rubrics.
- Especially the rubrics of “Explaining Relevant Clinical Information” showed the most significant improvement. These rubrics assess the objective aspects of response styles and thus can aid veterinarians in providing better explanations to pets’ companions.
- Our study is a groundwork that can lead to the development of advanced and larger-scale veterinary-specific models that can promote pets’ health and welfare accessibly and informatively.
Limitations & future works
1. Needs of specialists’ evaluation
- The validity of auto-evaluation should be improved by comparing it with assessments from clinical specialists (DVM, Ph.D.) on each response.
- Differential Diagnosis (DDX) scored lower than other rubrics due to the lack of gold standards such as top-k DDX assessed by specialists. To complement the evaluation approach, comparisons of the models’ top-k DDX to the gold standard will be adopted.
2. Upgrading the model for “Managing Patient Concerns”
- The effect of fine-tuning on ‘Managing Patient Concerns’ showed less improvement. Therefore, further research is planned to explore alternative learning datasets or prompts to enhance the subjective aspects of the response.
References
- Thirunavukarasu, A. J., Ting, D. S. J., Elangovan, K., Gutierrez, L., Tan, T. F., & Ting, D. S. W. (2023). Large language models in medicine. Nature medicine, 29(8), 1930-1940.
- Tu, T., Palepu, A., Schaekermann, M., Saab, K., Freyberg, J., Tanno, R., … & Natarajan, V. (2024). Towards conversational diagnostic ai. arXiv preprint arXiv:2401.05654.
Leave a comment